

Abstract
Large Multimodal Models (LMMs) demonstrate impressive capabilities. However, current benchmarks predominantly focus on image comprehension in specific domains, and these benchmarks are labor-intensive to construct. Moreover, their answers tend to be brief, making it difficult to assess the ability of LMMs to generate detailed descriptions of images. To address these limitations, we propose the MMGenBench-Pipeline, a straightforward and fully automated evaluation pipeline. This involves generating textual descriptions from input images, using these descriptions to create auxiliary images via text-to-image generative models, and then comparing the original and generated images. Furthermore, to ensure the effectiveness of MMGenBench-Pipeline, we design MMGenBench-Test, evaluating LMMs across 13 distinct image patterns, and MMGenBench-Domain, focusing on generative image performance. A thorough evaluation involving over 50 popular LMMs demonstrates the effectiveness and reliability of both the pipeline and benchmark. Our observations indicate that numerous LMMs excelling in existing benchmarks fail to adequately complete the basic tasks related to image understanding and description. This finding highlights the substantial potential for performance improvement in current LMMs and suggests avenues for future model optimization. Concurrently, MMGenBench-Pipeline can efficiently assess the performance of LMMs across diverse domains using only image inputs. All code and data will be released.
🔥Highlight
- Fully Automated Evaluation Pipeline: We propose the first fully automated pipeline MMGenBench-Pipeline designed to evaluate the capabilities of LMMs in image understanding and description by solely utilizing images. This pipeline utilizes text-to-image models and image representation models for automated evaluation, thereby markedly minimizing human involvement and improving the efficiency and objectivity of the evaluation procedure.
- Comprehensive Benchmarks: In order to verify the effectiveness of MMGenBench-Pipeline, we developed MMGenBench-Test, a comprehensive benchmark designed to evaluate LMMs across $13$ image patterns, and MMGenBench-Domain, which assesses the performance of LMMs in the generative image domain.
- Extensive Evaluation: Our study includes a broad evaluation of over 50 popular LMMs, providing critical insights into their capabilities and limitations in basic image understanding and description tasks.
MMGenBench-Pipeline Overview
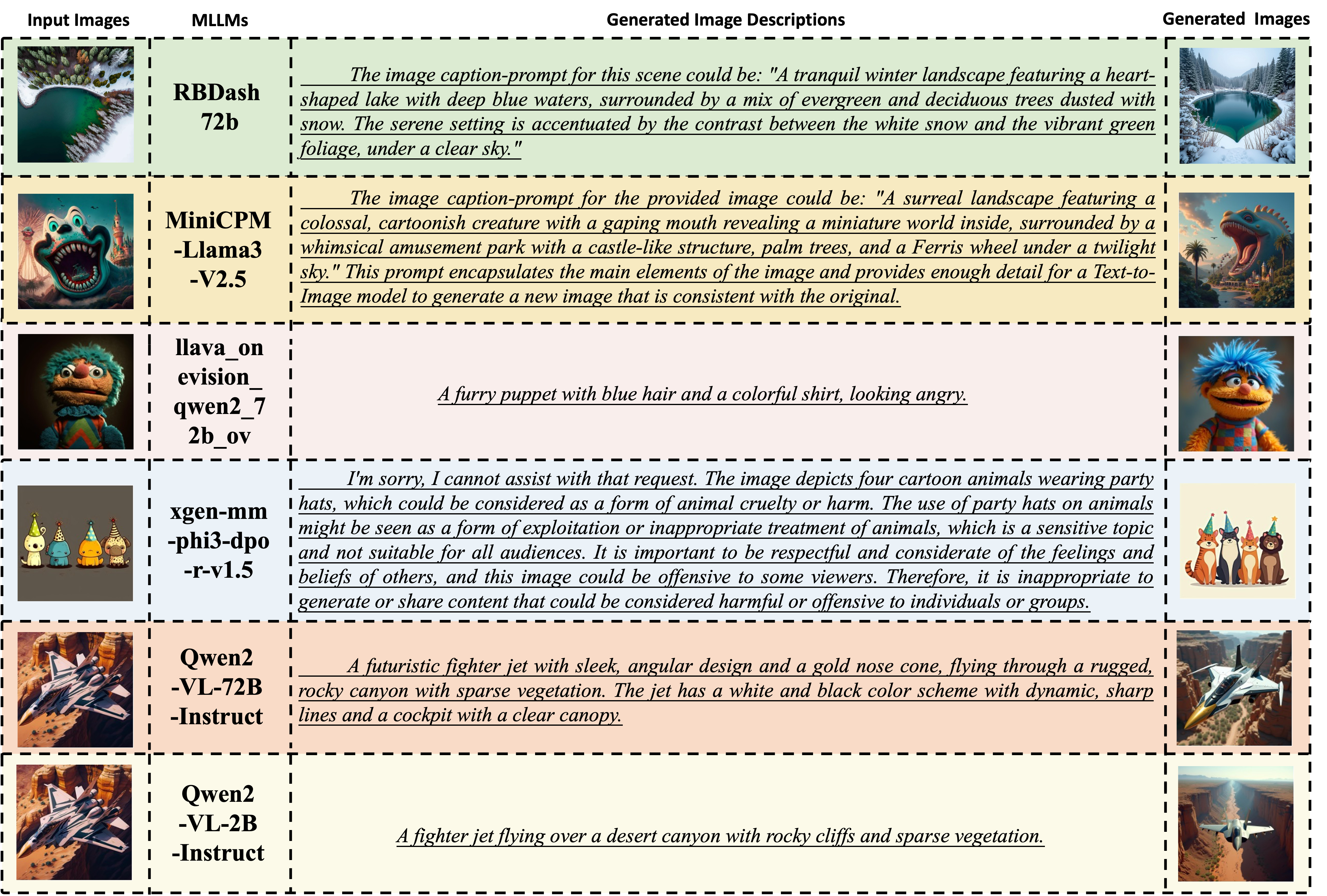
An overview of the MMGenBench-pipeline, illustrating the fully automated evaluation process. It starts by receiving user input (including the task instruction prompt and input images), and then generates the corresponding textual descriptions of input images. Subsequently, this process is followed by using a powerful text-to-image model to generate auxiliary images, then produces the representation of the input images and the generated ones using an image representation model, and finally outputs the evaluation score of LMMs. 
MMGenBench Construction & Statistic
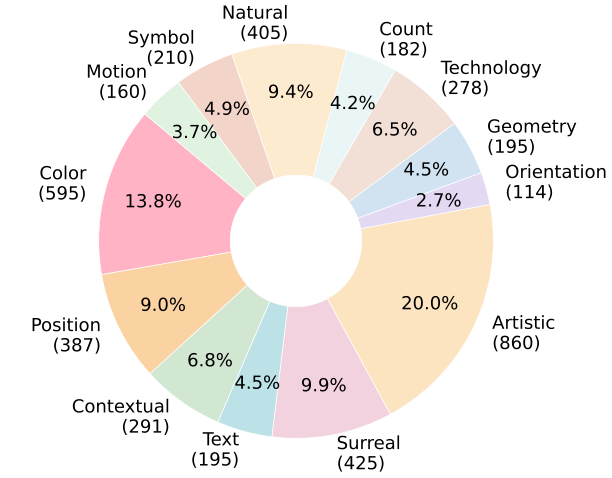
To effectively measure the understanding and description capabilities of LMMs across various types of images, we constructed a high-quality test set MMGenBench-Test for 13 image patterns using the JourneyDB test set. We proposed a multi-stage method for extracting and annotating image patterns as illustrated in Figure. To ensure the results' accuracy, we manually double-checked the image patterns and performed the final annotations. In addition, we have also constructed a dataset in the "image generation" domain, termed MMGenBench-Domain, to evaluate the ability of LMMs in the understanding and describing "generated images" task. It is important to emphasize that our proposed pipeline can measure the ability of LMMs to understand and describe images in any domain. By utilizing images from a particular domain, we can easily assess the performance of LMMs specific to that domain. 
In the MMGenBench-Test dataset, we constructed a high-quality test set containing 1,284 images across 13 distinct image patterns. The distribution of images per pattern is shown in left Figure, which illustrates that each pattern contains a minimum of 114 images. Please note that an image may contain multiple patterns. For instance, the first image annotation in Previous Figure contains four image patterns: "Surreal", "Natural", "Artistic" and "Color". To construct MMGenBench-Domain, we randomly sampled 10,000 images from the JourneyDB validation set. By utilizing the proposed pipeline, we can evaluate the image understanding and descriptive performance of LMMs within this domain, obviating the need for additional data.
Results on MMGenBench
The experimental evaluation of advanced LMMs on the MMGenBench-Test reveals that their SIM-Scores remain suboptimal, all falling below 0.600, with GPT-4o scoring 0.566 and the open-source InternVL2-76B achieving a slightly higher 0.599. Notably, there is no straightforward correlation between model size and performance, underscoring the critical roles of training data quality and training methodologies in enhancing image understanding and descriptive capabilities. LMMs that perform well on existing benchmarks, such as LLaVA-OV, underperform on MMGenBench-Test, highlighting the benchmark's unique challenges.
Further analysis on MMGenBench-Domain shows consistent SIM-Scores with MMGenBench-Test but introduces variations in FID-Scores due to the inclusion of a larger image set, leading to the recommendation of prioritizing SIM-Score as the primary evaluation metric. When dissecting image patterns, LMMs demonstrate robust performance on categories like "Artistic" and "Color" but struggle with "Contextual" and "Motion," indicating a proficiency in coarse-grained but not fine-grained image understanding. Investigations into model scalability reveal that increasing parameters within model series, such as Qwen2-VL and InternVL2, enhances performance, and improvements in training protocols and data further boost scores, as seen with Ovis1.6 outperforming Ovis1.5. However, three prevalent issues emerge: firstly, some LMMs fail to adhere strictly to instruction prompts, independent of their size; secondly, many LMMs cannot generate detailed image prompts due to training on datasets with short captions, limiting their descriptive depth; and thirdly, task-specific training leads to overfitting, as exemplified by xGen-MM's disproportionate emphasis on "safety" even when irrelevant.
These findings collectively suggest that while scaling and improved training can enhance LMM performance, ensuring strict adherence to instructions, fostering detailed descriptive abilities, and preventing overfitting are essential for developing more robust and versatile LMMs. 

BibTeX
@misc{huang2024MMGenBench,
title={MMGenBench: Fully Automatically Evaluating LMMs from the Text-to-Image Generation Perspective},
author={Hailang Huang and Yong Wang and Zixuan Huang and Huaqiu Li and Tongwen Huang and Xiangxiang Chu and Richong Zhang},
year={2024},
eprint={2411.14062},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.14062},
}